Streaming Multiprocessors: Scheduling and Execution
September 20, 2025
Modern GPUs achieve their massive parallel performance through Streaming Multiprocessors (SMs). An SM is the fundamental compute block of the GPU, containing everything needed to execute thousands of threads in parallel: cores for arithmetic, fast local memory, registers, and schedulers. By replicating SMs across the GPU die, manufacturers scale performance from tens of gigaflops into the multi-petaflop range. For example, NVIDIA’s A100 GPU integrates 108 SMs, while the newer H100 contains 132. Understanding the role of SMs is critical to understanding why GPUs excel at deep learning and other workloads that demand large-scale parallelism.
Why SMs Matter for Machine Learning
Streaming multiprocessors are central to GPU efficiency because they’re where actual computation happens. Each SM provides the execution environment for tens of thousands of threads, houses both general-purpose CUDA cores and specialized tensor cores, and manages fast local storage through registers and shared memory. They also include schedulers that interleave thousands of threads so the cores stay busy even when some threads are waiting on data. Without SMs, the GPU’s cores would be isolated units — SMs are what bring them together into coordinated, highly parallel engines.
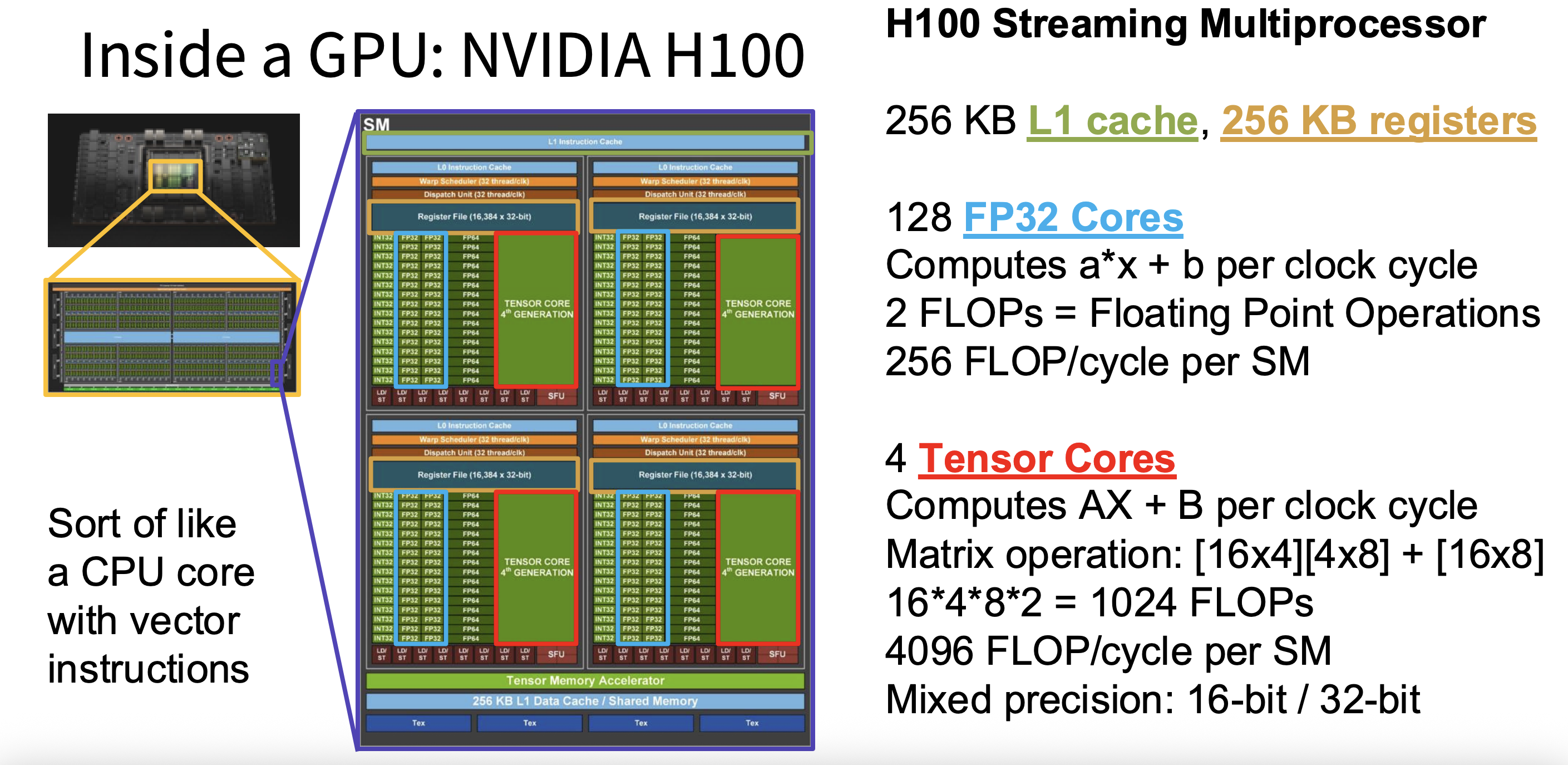
Figure 1: H100 SM floorplan highlighting each warp scheduler’s resources—256 KB L1/SMEM, 16k-register files, 128 FP32 ALUs, and four 4th-gen tensor cores delivering 4,096 mixed-precision FLOPs per cycle.
Anatomy of an SM
Each SM integrates a variety of hardware resources that work together to execute threads efficiently. At the core are CUDA cores — general-purpose units that handle FP32, FP64, and integer arithmetic, taking care of everything from simple indexing and control flow to basic math. Alongside them are tensor cores, which are purpose-built for matrix multiply-accumulate operations of the form . Tensor cores work on small matrix tiles in reduced precision (FP16, BF16, or FP8) with results accumulated in FP32, enabling hundreds of floating-point operations per cycle — the real workhorse of modern neural network training.
Each thread also has access to registers, the fastest storage on the chip. Registers are private to each thread and hold the values actively being computed; all arithmetic instructions operate on them. Shared memory and the L1 cache provide a somewhat larger but still very fast region that all threads in a block can access together — especially useful for tiled matrix multiplication, where multiple threads collaborate on the same data. Warp schedulers keep everything moving by deciding which groups of 32 threads (warps) execute in each cycle, switching between warps to hide latency whenever one is stalled waiting on memory. Finally, load/store units handle data transfers between the SM and higher levels of the hierarchy like L2 and HBM.
Together, these resources form a self-contained compute cluster. The GPU die is built by replicating SMs, enabling the scaling that makes GPUs effective for workloads ranging from graphics to deep learning.
Parallel Execution in an SM
One of the defining features of an SM is its ability to manage massive numbers of threads. Threads are grouped into warps, and warps are organized into thread blocks. An SM can run multiple blocks at once, with each warp scheduler interleaving instructions across warps to keep the cores busy.
This design allows GPUs to hide latency . For example, when one warp is stalled waiting for data from memory, the scheduler can immediately switch to another warp that is ready to execute. This rapid context switching is lightweight and enables the SM to keep its CUDA and tensor cores operating near peak throughput.
In a typical deep learning kernel, this pipeline looks like: a tile of weights and activations is loaded from L2 or HBM into shared memory, then warps of threads copy their individual elements into registers. Tensor cores then perform multiply-accumulate operations on those register values, storing intermediate results back in registers or shared memory as needed. Once the computation is complete, the final results are written to L2 and eventually back to HBM.
Real World Implications for ML
More SMs means more parallel execution — newer GPUs with higher SM counts can train larger models or process more data per unit time. But raw SM count isn't everything. Register usage, shared memory allocation, and warp scheduling all directly affect how many threads can be active on an SM at once (called occupancy). Poor tuning can leave cores underutilized even when a GPU looks powerful on paper. Ultimately, it comes down to balance: the interaction between compute units and memory resources inside each SM determines whether a kernel is compute-bound or memory-bound, and optimizing that relationship is what separates efficient GPU code from inefficient GPU code.