Multi-GPU Training, Part 2: Fully Sharded Data Parallelism
September 25, 2025
Data Parallelism (DP) is simple and effective, but it assumes that every GPU stores a full copy of the model weights, gradients, and optimizer states. For multi-billion parameter models, this memory duplication quickly becomes infeasible.
Fully Sharded Data Parallelism (FSDP) solves this problem by splitting model states across GPUs. Instead of each GPU storing the entire model, weights, gradients, and optimizer states are sharded so that each GPU only holds a fraction. During training, the required parameters are dynamically communicated, used, and then discarded — dramatically reducing memory usage while keeping the training mathematically equivalent to DP.
Why FSDP Matters
To understand why this matters, consider what gets stored for each parameter when training with Adam. You need the weight itself, its gradient, and two optimizer states (). At FP16 precision (2 bytes per number), that adds up to 8 bytes per parameter. For a model with 10 billion parameters, that’s roughly 80 GB of memory — enough to max out an entire NVIDIA A100 on its own.
How FSDP Works
In FSDP, each parameter shard has a designated owner GPU. That GPU is responsible for storing the parameter’s value, its gradients, and optimizer states. Training then proceeds layer by layer.
Before the forward pass for a given layer, the owning GPU broadcasts its weights to all other GPUs. All GPUs then compute the forward pass using those shared weights. Once that’s done, each GPU discards its local copy of to free memory — there’s no point holding onto weights that won’t be needed until backpropagation.
Before the backward pass, the owning GPU broadcasts again. Each GPU computes its local gradients for that shard, then discards the temporary copy. Next, each GPU sends its local gradient shard back to the owning GPU in a reduce-scatter operation, and the owner aggregates them into the global gradient for . Finally, the owning GPU uses its shard of optimizer states to update its portion of the parameters.
An important optimization is to overlap communication with computation. While computing the forward pass with , the GPU can prefetch in the background. Similarly, while backpropagating through , GPUs can simultaneously reduce gradients for . This overlap ensures that communication overhead doesn’t dominate training time.
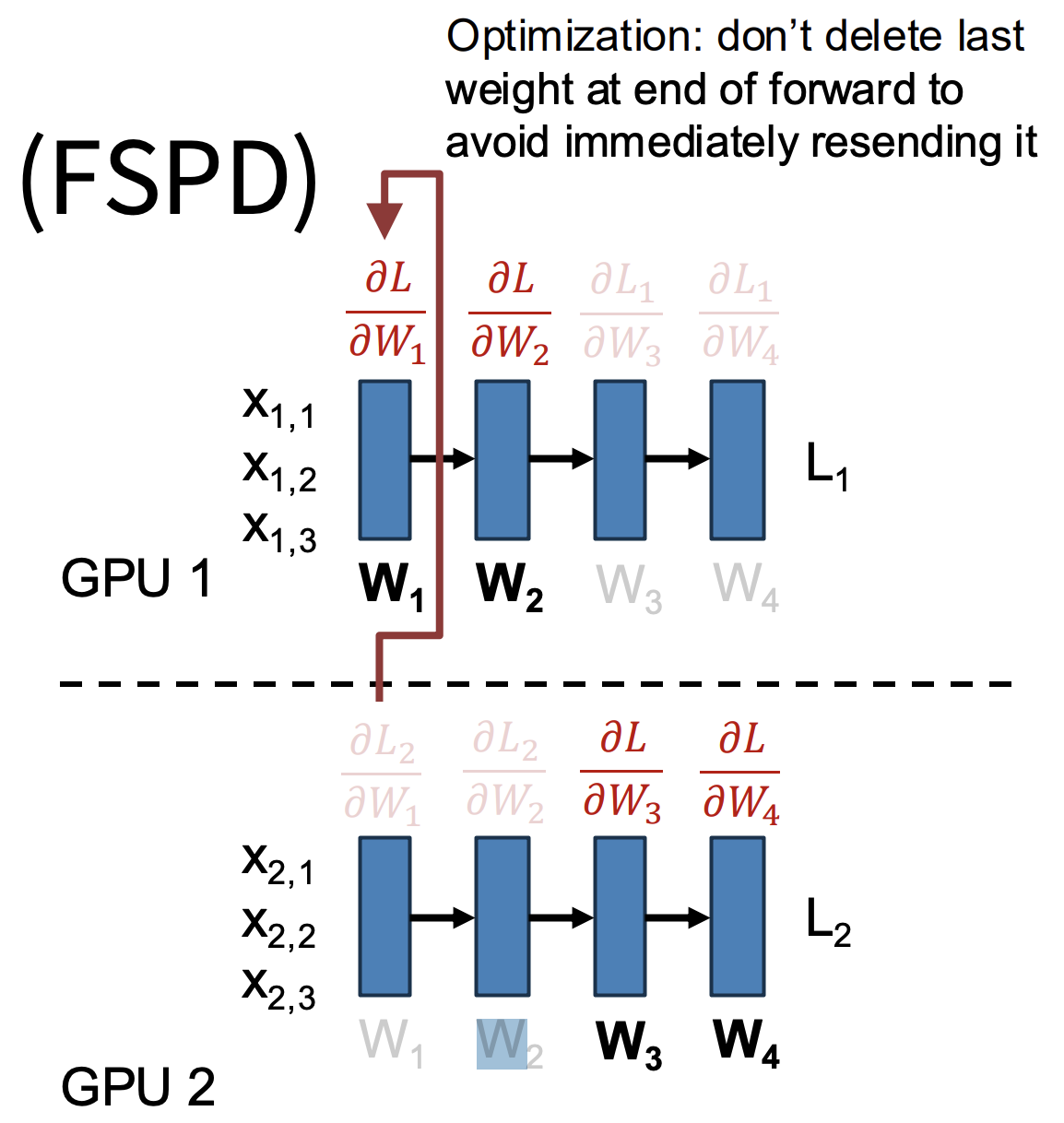
Figure 1: Example of how Fully Sharded Data Parallel (FSDP) training splits a model across GPUs. GPU 1 holds weights W₁–W₂, while GPU 2 holds W₃–W₄. Each GPU only computes gradients for its own shard, then shares the results as needed. A small optimization is shown here — the last weight from the forward pass isn’t deleted right away to avoid having to resend it immediately during backpropagation.
Memory Efficiency
In classic data parallelism, every GPU stores the full model, so memory per GPU scales as:
With FSDP across M GPUs, that footprint is divided across the cluster, bringing memory per GPU down to:
Advantages
FSDP's biggest benefit is the memory savings it enables. By eliminating redundant copies of weights, gradients, and optimizer states, it makes it practical to train models with hundreds of billions or even trillions of parameters — something that's simply not possible with standard data parallelism. It's also compatible with overlap strategies, so compute and communication can be pipelined to keep GPUs busy.
Limitations
The tradeoff is that FSDP requires frequent broadcasts and reduce-scatter operations across GPUs, which adds communication overhead. It's also more complex to implement and schedule compared to plain DP. For smaller models that fit comfortably on a single GPU, that added complexity isn't worth it — standard data parallelism is simpler and faster in those cases.