Hierarchical Text-Conditional Image Generation with CLIP Latents
September 15, 2025
This paper proposes unCLIP, a hierarchical text-to-image system that leverages CLIP’s joint image–text latent space to improve generation quality and control. The approach splits generation into two stages: (1) a prior that predicts a CLIP image embedding from a caption, and (2) a diffusion decoder that maps that embedding to pixels (with upsamplers for high resolution). By explicitly generating in CLIP latent space before decoding to images, unCLIP achieves higher sample diversity with comparable photorealism to prior systems like GLIDE, while also enabling intuitive edits such as semantic variations, image interpolations, and language-guided “text diffs.”
Architecturally, the decoder conditions on CLIP image embeddings (and optionally text), and the prior can be implemented either autoregressively or as a diffusion model—with the diffusion prior proving more compute-efficient and higher quality. The result is a model that better preserves semantics and style across samples, mitigates guidance-induced mode collapse, and provides a practical handle for zero-shot manipulations through movements in the CLIP space. unCLIP helps clarify what CLIP encodes (and omits), and showcases a diversity-fidelity trade-off that favors more varied, yet realistic, generation.
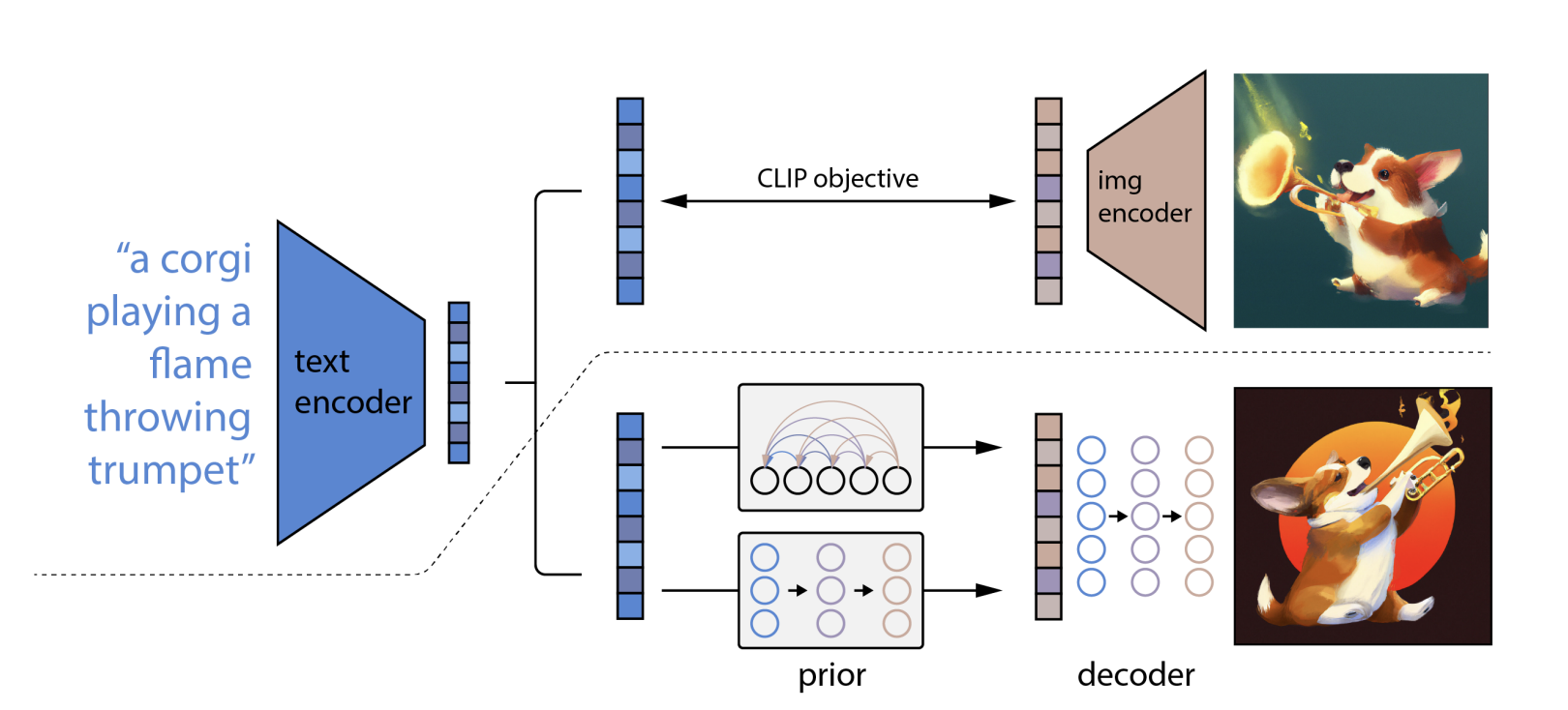
Figure 1: (found in reference below) A high-level overview of unCLIP. Above the dotted line, we depict the CLIP training process, through which we learn a joint representation space for text and images. Below the dotted line, we depict our text-to-image generation process: a CLIP text embedding is first fed to an autoregressive or diffusion prior to produce an image embedding, and then this embedding is used to condition a diffusion decoder which produces a final image. Note that the CLIP model is frozen during training of the prior and decoder.
Methods
The unCLIP framework is built as a two-stage system. First, a prior generates a CLIP image embedding from a text caption. Then, a decoder uses that embedding to synthesize a high-resolution image. This separation lets the model handle semantics (what the image should mean) and pixels (how the image should look) in distinct steps.
Decoder
The decoder is a diffusion model that transforms random noise into an image, guided by CLIP embeddings. To ensure the model respects the latent representation, CLIP features are injected both into the timestep embeddings and as extra context tokens.
To sharpen results, the team used classifier-free guidance, randomly dropping text or embeddings during training so the guidance strength can be tuned at inference.
Images are produced in stages:
- Upsampled to
- Upsampled again to
These upsamplers are trained with noise corruption (blur and degradations) for robustness, and they don’t require text conditioning since the low-resolution image already encodes the scene.
Priors
The prior is what makes text-to-image generation possible in unCLIP. While the decoder can turn a CLIP image embedding into pixels, captions don’t come with these embeddings. The prior learns to map from a caption to a CLIP image embedding, providing the semantic “bridge” that connects language to images.
Two variants were explored:
-
Autoregressive (AR) Prior
- Compress CLIP embeddings with PCA (from 1024 → 319 dimensions).
- Quantize into discrete codes, then predict them sequentially with a Transformer.
- Adds a dot-product token to bias toward higher text–image alignment.
-
Diffusion Prior
- Works directly in continuous embedding space.
- During training, noise is added to real CLIP embeddings, and the model learns to denoise them back.
- At inference, starts from pure noise and denoises into a caption-consistent embedding.
- Found to be more efficient and higher quality than the AR prior.
Why it Matters
By generating in CLIP latent space first, unCLIP produces embeddings that preserve semantics and style before rendering pixels. This design improves diversity (multiple images per caption), prevents collapse under guidance, and enables powerful editing tools like variations, interpolations, and text-driven modifications.
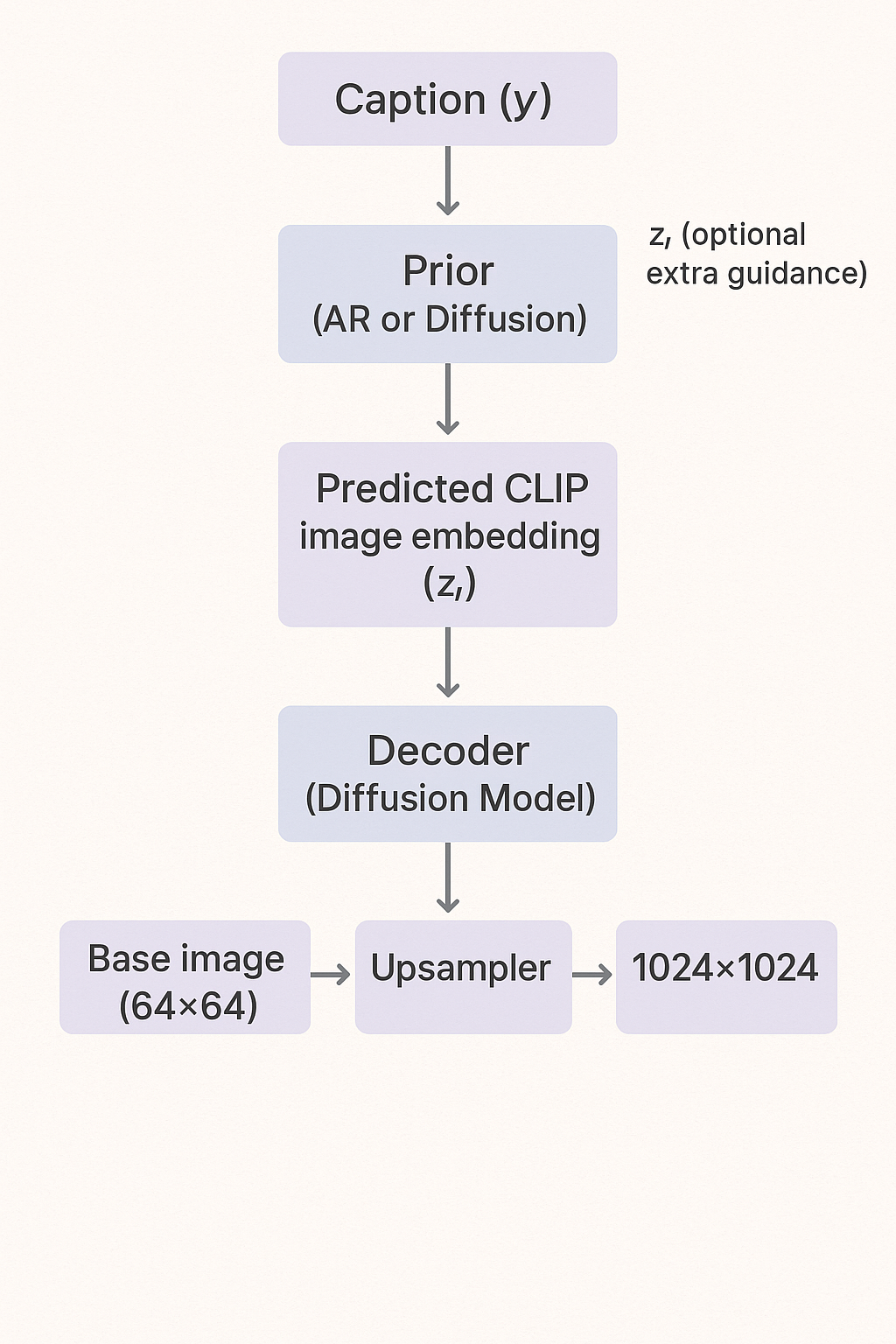
Figure 2: unCLIP generation pipeline: captions are mapped into CLIP latent space by a prior, then decoded and upsampled into high-resolution images.
Image Manipulations
A key feature of unCLIP is that every image can be represented as a bipartite latent :
- is the CLIP image embedding — the semantic/style summary that CLIP recognizes
- is obtained via DDIM inversion of the original image using the decoder (conditioned on ) and stores the remaining fine-grained details needed for reconstruction.
With this representation, unCLIP enables three intuitive manipulations:
Variations
Starting from , we decode with DDIM and set during sampling. The result is a family of images that preserve the semantic core and style (e.g., “a clock in a surreal painting”) while naturally changing non-essential details (pose, background clutter, brush strokes). With , the model reconstructs the original image exactly.

Figure 3: Variations of an input image by encoding with CLIP and then decoding with a diffusion model. The variations preserve both semantic information like presence of a clock in the painting and the overlapping strokes in the logo, as well as stylistic elements like the surrealism in the painting and the color gradients in the logo, while varying the non-essential details.
Interpolations
To blend images and , we interpolate their CLIP latents with spherical interpolation (SLERP):
We then choose how to handle image-level detail:
- Path A (endpoint-faithful): spherically interpolate the inverted latents → smooth trajectory whose endpoints reconstruct and .
- Path B (diverse paths): fix a random for all → infinite possible trajectories; endpoints won't perfectly match, but midpoints look richer and more varied.

Figure 4: Variations between two images by interpolating their CLIP image embedding and then decoding with a diffusion model. We fix the decoder seed across each row. The intermediate variations naturally blend the content and style from both input images.
Text Diffs (language-guided edits)
Because CLIP embeds images and text in the same latent space , we can apply caption-driven edits. Given a current description and a target description , we compute the text diff vector:
Then spherically interpolate the image latent towards : . Decode each while fixing to keep low-level rendering stable. This yields smooth zero-shot edits like winter → fall,” “adult lion → lion cub,” “photo → anime.”

Figure 5: Text diffs applied to images by interpolating between their CLIP image embeddings and a normalised difference of the CLIP text embeddings produced from the two descriptions. We also perform DDIM inversion to perfectly reconstruct the input image in the first column, and fix the decoder DDIM noise across each row.
Conclusion
unCLIP shows how powerful generative models can become when paired with strong representation learning. By combining CLIP’s joint text–image latent space with diffusion decoders, unCLIP is able to generate diverse, high-quality images from captions, reconstruct and vary existing images, and even perform zero-shot edits guided by language.
The key innovation is the two-stage design :
- The prior turns captions into CLIP image embeddings, grounding text in visual semantics.
- The decoder maps those embeddings into pixels, producing photorealistic or artistic outputs.
This separation makes the system more flexible: priors handle the text–image mapping, while decoders specialize in image quality. The result is a model that not only competes with earlier text-to-image systems like GLIDE and DALL·E, but also introduces new creative tools like semantic variations, interpolations, and text-guided modifications.
References
- Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with CLIP latents. arXiv preprint arXiv:2204.06125. https://cdn.openai.com/papers/dall-e-2.pdf