Learning Transferable Visual Models From Natural Language Supervision
April 25, 2025
Original paper: CLIP paper on OpenAI
Imagine teaching a camera to “read” the internet the way we do—absorbing memes, headlines, product reviews, and photo captions—then asking it to recognize anything you can describe in plain English. That’s the central ambition behind “Learning Transferable Visual Models From Natural Language Supervision”, the 2021 paper that first introduced CLIP. Instead of training a model on a fixed checklist of labels (the ImageNet playbook), the authors feed it 400 million image–caption pairs scraped from the wild. The result is a system that can spot everything from “a corgi wearing sunglasses” to “the cover of a 1980s jazz album” without ever being explicitly shown those categories. How is this done?
Here is the model architecture:
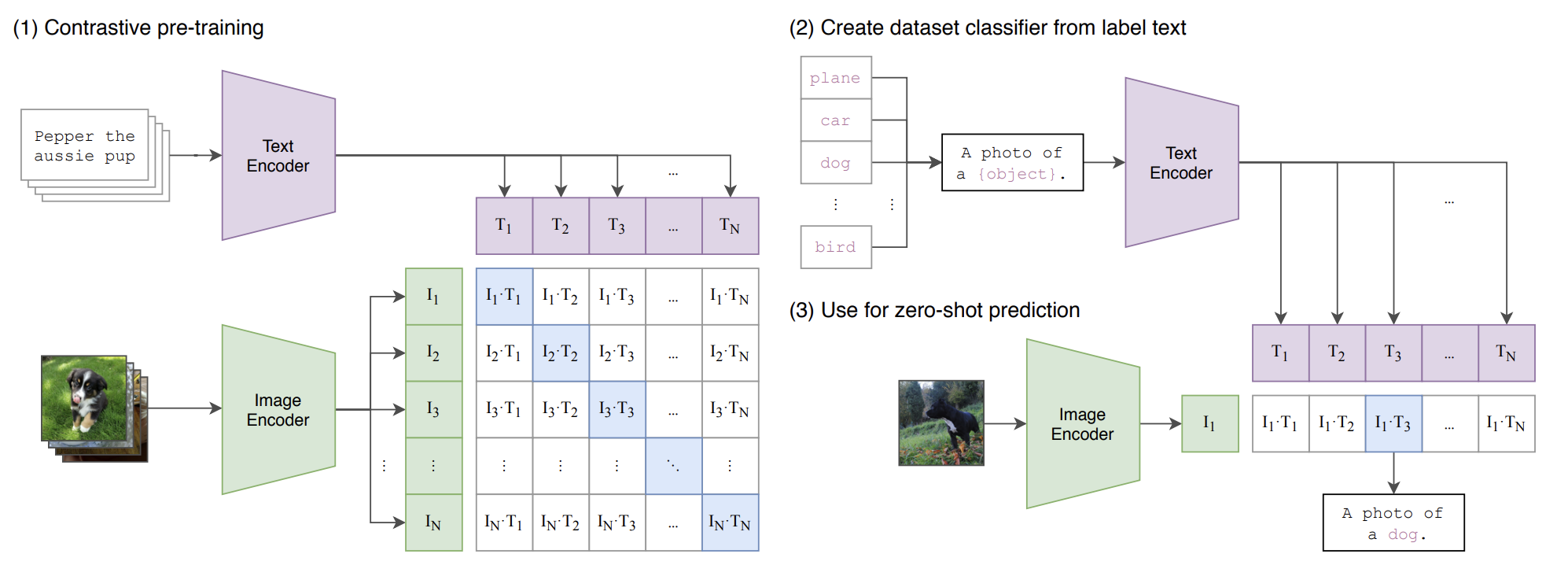
Figure 1: CLIP jointly trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, text) training examples. At test time the learned text encoder synthesizes a zero-shot linear classifier by embedding the names or descriptions of the target dataset’s classes.
Existing state-of-the-art models (e.g. , ResNeXt-101, EfficientNet-L2) use huge compute budgets (19-33 GPU/TPU years), and they still only learn 1000 ImageNet classes. Therefore, learning open-world concepts from natural language supervision seemed daunting without extreme computational efficiency. As such, training efficiency became a core design goal for CLIP.
A failed approach to this problem included jointly training an image CNN and a text transformer to predict the exact caption for an image. This proved to be extremely difficult due to the wide variety of descriptions that can be associated with a given image.
Instead, the approach became to predict which text matches which image rather than predicting what the given body of text says.
Given a batch of (image, text) pairs, the task becomes identifying the correct real pairs. To do this, CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity for the embeddings of the correct pairs, while minimizing the cosine similarity for the embeddings of the pairs. It should be noted that we perform a linear projection on each encoder's embedding into the multi-modal embedding space.
A symmetric cross-entropy loss was optimized over the similarity scores of the pairs. Overall, switching from caption prediction to contrastive pairing resulted in a 4x faster learning rate for zero-shot transfer to ImageNet.
For implementation purposes, we have the pseudocode below:

Figure 2: NumPy-like pseudocode for the core of an implementation of CLIP.
As specified in the paper, the loss function used is a symmetric cross-entropy loss and is known as the multi-class N-pair loss , which was popularized for contrastive representation learning by Oord et al. (2018) as the InfoNCE loss, and was recently adapted for contrastive (text, image) representation learning. The loss function is defined below as:
Given a set of random samples containing one positive sample and . Moreover, (similarity-score between an image and a given piece of text), where are the normalized image and text embeddings, represents the cosine between the text and image embeddings, and is the learned temperature parameter. , represents the similarity-score of the "correct" image-text pair, while represents the sum of all similarity scores between 1 image and all corresponding text labels.
When increases (similarity-score increases), the numerator grows meaning that our loss goes down. In effect, this means that the true image-text pairs move closer in the shared space. However, every where contributes to the denominator. To keep the denominator small, the model must drive those "incorrect" similarity scores down. As such, the mismatched image-text pairs move farther apart.
To compute the loss, we take each row of the logits matrix (containing similarity scores between each image and caption), run a softmax over that row (treating the row as a probability distribution), and compute the cross-entropy against the one-hot label that picks out the true caption. We can interpret this as "given image i, which of the captions correctly matches". Likewise, we then take each column of the logits matrix, run a softmax over that column, and compute the cross-entropy against the one-hot label that picks out the true image. Therefore, we can interpret this as "given caption j, which of the images does it belong to?".
By averaging the two losses, we get a symmetric objective that teaches the image encoder to retrieve its matching text, and teaches the text encoder to retrieve its matching image; both in the same embedding space. Through this, CLIP's zero-shot performance is significantly better than that of models trained on the ImageNET datasets, who perform rather poorly when asked to identify classes not found in their training data.
Overall, CLIP represents a fundamental shift in how we think about visual learning. By discarding rigid labels and embracing the messiness of natural language, it builds a vision system that can reason about the world in much the same way humans do—through flexible, open-ended descriptions. More than just an efficiency gain, this approach unlocks a new kind of generality in machine learning: one where describing a task in words might be enough to solve it.
Let it be noted that the remainder of the paper dives into the results of CLIP, specifically its robustness to a variety of datasets in comparison to ImageNet trained models (supervised learning). Feel free to check it out at the link above!